
Beyond the scaling laws: Why the next leap in AI requires an architectural revolution
The era of revolutionary leaps in AI is giving way to incremental refinements of the transformer architecture, pushing the industry toward a "local maximum." The next true breakthrough will require a departure from the current architectural blueprint and a shift toward new paradigms.
Beyond the scaling laws: Why the next leap in AI requires an architectural revolution
This piece is part of the Algorithma whitepaper series. This means it is a longer read that deep-dives into a specific topic, covering some of the more technical aspects of artificial intelligence.
The world’s most advanced foundational models are pushing benchmarks higher, but the era of transformative leaps may be giving way to iterative refinements of an architecture near its limits. This shift will reshape the competitive landscape: big players will move up the value chain with vertical applications, while the vibe-coded LLM wrapper ecosystem consolidates. For enterprises, the real value will come from deploying foundation models as bespoke engines for business process automation. But, this also means that there is significant value to capture from leveraging these capable models across efficiency, innovation and customer interaction.
2025 has been marked by a relentless cadence of foundation model releases from the world's leading artificial intelligence companies. Each announcement, from OpenAI's GPT-5 to Meta's Llama 4 and Mistral's specialized systems, has been accompanied by claims of state-of-the-art performance and new benchmarks being surpassed. However, a critical analysis of these developments reveals a telling trend: the era of revolutionary, paradigm-shifting leaps in capability appears to be giving way to a period of sophisticated, yet incremental, refinement. The latest models are marvels of engineering, but they are primarily optimizations of the transformer architecture. The focus has shifted from discovering fundamentally new capabilities to engineering more efficient and powerful applications of existing ones, suggesting the industry has reached a “local maximum” and that the next true breakthrough will require a departure from the current architectural blueprint. As one AI investor noted, there is significant “inertia around transformer architectures,” with so much invested in optimizing them that the industry often favors safer incremental upgrades over risky architectural leaps.
OpenAI's GPT-5 is incremental
OpenAI's launch of GPT-5 was positioned as a "significant leap in intelligence" over all previous models [1]. CEO Sam Altman described interacting with it as speaking to a "legitimate PhD-level expert" [2]. Yet, beneath the marketing, the architecture of GPT-5 reveals a strategic engineering solution to the persistent trade-off between speed and capability, rather than a fundamental architectural evolution.
The GPT-5 offering is not a single, monolithic model. Instead, it is a "unified system" composed of multiple components: a fast and efficient gpt-5-main model (the successor to GPT-4o) for handling most queries, a more powerful gpt-5-thinking model (the successor to the o3 series) for deeper reasoning, and a real-time router that intelligently directs user prompts to the appropriate model based on complexity and intent [3]. This design allows GPT-5 to allocate more computation to complex tasks, edging closer to an “agentic” system that can carry out multi-step instructions [4]. This routed system is a clever way to optimize user experience and resource allocation, but it is an enhancement of the deployment strategy, not the core technology.
On standard benchmarks, GPT-5's performance is undeniably impressive. It sets new state-of-the-art scores in critical domains, achieving 94.6% on the AIME 2025 math competition, 74.9% on the SWE-bench Verified coding challenge, and 46.2% on the HealthBench Hard medical query dataset [5]. The improvement in coding is particularly stark when compared to its predecessor, GPT-4o, which scored only 30.8% on SWE-bench [6].However, these gains represent a "leveling up" of existing skills rather than the emergence of entirely new ones. The launch itself was not seamless; it was marked by technical failures in the routing system and a wave of user complaints, with some subscribers requesting the ability to revert to GPT-4o, suggesting that the system's complexity is becoming a challenge to manage effectively [7].
Meta's Llama 4 is open-source efficiency at scale
Meta's release of the Llama 4 series, particularly the Llama 4 Scout and Llama 4 Maverick models, showcases a similar focus on optimization and scaling efficiency within the open-source community. The headline innovation is the adoption of a Mixture-of-Experts (MoE) architecture [8]. MoE is a scaling strategy that allows for a massive increase in a model's total parameter count, Llama 4 Maverick has 400 billion total parameters, without a proportional rise in computational cost during inference. This is achieved by dividing the model into specialized "experts" and activating only a small fraction of them for any given token [9]. Like OpenAI's router, MoE is an engineering solution designed to make the Transformer architecture more economically viable at an enormous scale. This focus on efficiency was also evident in Meta's Llama 3.3, a 70B parameter model that matched the performance of an earlier 405B model, signaling a strategic shift toward efficiency gains over pure scaling.
Llama 4 also introduces a "natively multimodal" design using an "early fusion" technique to integrate vision and text tokens from the pre-training stage, along with an industry-leading 10 million token context window.9 While a 10M token context is a significant engineering feat that unlocks new use cases for processing vast amounts of information, it is an extension of an existing capability, not the creation of a new one. In the competitive landscape, Llama 4 Maverick is positioned as outperforming models like GPT-4o and Gemini 2.0 Flash on several key benchmarks while being more computationally efficient [10]. This reinforces the narrative of a fierce, but incremental, arms race centered on benchmark supremacy and cost-performance ratios within the established paradigm.
Mistral, Google, and Anthropic: Specialization and diversification
The strategies of Mistral, Google, and Anthropic in 2025 further illustrate the maturation of the transformer architecture. Rather than pursuing a single, ever-larger generalist model, these companies are diversifying. Mistral has released a suite of specialized, enterprise-focused models, including Codestral for coding, Magistral for enhanced reasoning, and Voxtral for speech understanding [11]. Its Magistral family focuses on transparent, step-by-step reasoning to improve interpretability in high-stakes domains like law and finance. Its flagship reasoning model, Mistral Next, is explicitly designed with a "reasoning-first architecture" to compete with GPT-4 and Claude 3, but it remains an LLM at its core [12]. This specialization suggests a market realization that tailoring the Transformer for specific domains may yield more practical value than simply scaling it indefinitely.
Google has adopted a similar ecosystem-centric approach, deeply integrating its Gemini 2.5 family of models into its vast suite of products, including Search, Photos, and NotebookLM. An experimental "Deep Think" mode allows Gemini to devote extra reasoning steps to difficult math or coding problems, achieving top scores on benchmarks like the USAMO math Olympiad [13]. This strategy prioritizes utility and user experience over raw benchmark performance. The release of specialized models like MedGemma for healthcare applications further underscores this trend toward diversification [13]. A notable exception in Google's portfolio is Genie 3, a generative "world model" capable of creating interactive environments from prompts; a development that hints at a potential architectural path beyond the current LLM paradigm [14].
Similarly, Anthropic's Claude 4 models emphasize "long-horizon thinking," designed to maintain focus across complex, multi-step workflows without losing context. The collective progress of these frontier models, when viewed side-by-side, paints a clear picture. The performance gaps between the top models are narrowing, and the primary battleground has shifted toward efficiency, specialization, and system-level engineering.
This competitive landscape has given rise to a new user-facing workflow: "vibe coding." Models like GPT-5 are now proficient enough at coding to generate entire applications from simple, high-level natural language prompts [2]. This paradigm shifts the developer's role from writing syntax to guiding an AI's "vibe" through conversational prompts and iterative evaluation. This workflow is a direct consequence of incremental progress; the models are quantitatively better at generating code but not yet qualitatively capable of autonomous software development. The continued necessity of a human-in-the-loop to direct, debug, and verify the output is a clear indicator of a technology that has become a more powerful tool but has not yet made the leap to a true intelligent agent [15].
The law of diminishing returns in action
The incremental nature of recent model improvements is not merely a matter of perception; it is a direct consequence of the economic and technical realities of the scaling laws that have governed AI progress for the past half-decade. The principle that model performance improves predictably with more data, more parameters, and more compute was the engine of the generative AI revolution [16]. Now, however, we may be confronting the reality of diminishing returns, where each marginal gain in performance requires an exponential increase in resources, pushing the current paradigm toward an unsustainable wall.
Training a frontier foundation model has become an undertaking of astronomical expense. The training run for GPT-4 is estimated to have cost over 100 MEUR and required approximately 55 times the computational resources of GPT-3 [17]. While the resulting performance jump was significant; for example, on the MMLU benchmark, GPT-4 scored 86.4% compared to GPT-3's 43.9%. The gain was not proportional to the 55 times increase in compute [17]. This trend has continued, with each subsequent percentage point of improvement on benchmarks demanding ever-larger investments [18].
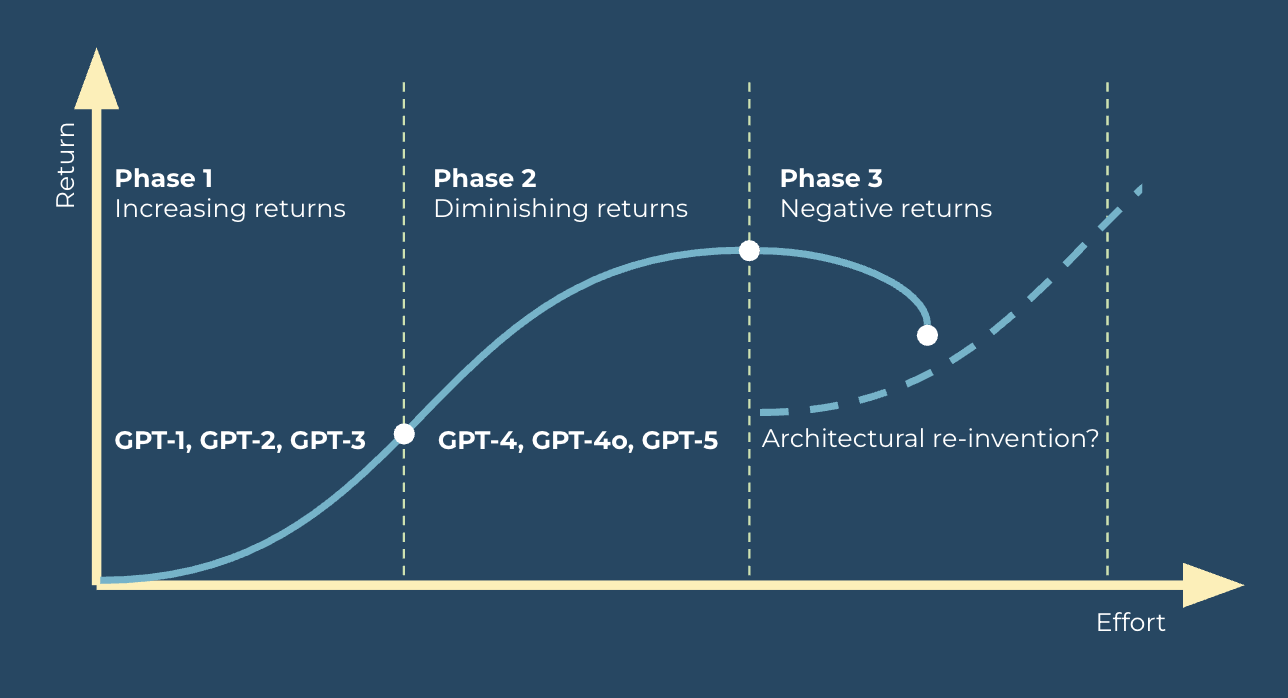
The law of diminishing returns
The scaling laws that powered the rise of generative AI may be running into diminishing returns. The industry is moving from an age of brute-force scaling to an age of architectural re-invention.
Note, OpenAI GPT-models used as illustration, the same applies to the other models as well.
Phase 1: Increasing returns
This phase represents the early days of large language models, where a small amount of effort (in the form of increased parameters and data) led to massive, revolutionary leaps in capability. This was the era of foundational discoveries.
Phase 2: Diminishing returns
This phase marks the current state of the AI industry. The models are incredibly sophisticated, but each new iteration requires a massive, exponential increase in effort (compute, data, and engineering) to achieve only marginal, incremental gains in performance. The "point of diminishing returns" may be where the industry now finds itself.
E.g. The leap from GPT-3 to GPT-4 was significant, but it required a 55 times increase in compute. GPT-5 was more a consolidation of models.
Phase 3: Negative returns
This phase represents a potential future scenario where continued effort on the current architectural paradigm not only yields diminishing returns but could actively lead to negative outcomes.
This economic strain is compounded by a looming data bottleneck. Experts have warned for years that the supply of high-quality, publicly available text data on the internet is finite and rapidly being exhausted [19]. As labs run out of novel human-generated data, they are forced to turn to lower-quality sources or use synthetic data generated by other AI models. This practice risks a feedback loop of errors and "model collapse," where models trained on the output of other models begin to degrade in quality [17]. The scaling law, which once provided a clear and predictable path to progress, has now become a double-edged sword; it reliably predicts that the next step forward will be prohibitively expensive and reliant on a dwindling resource.
This economic reality is mirrored in the models' performance. The dramatic leaps in capability that characterized earlier generations have been replaced by a slow grind up the leaderboards. The MMLU benchmark illustrates this: after GPT-4's massive jump to 86.4% in 2023, subsequent frontier models from all major labs have been incrementally inching toward the human-expert level of approximately 90% [17]. This flattening of the performance curve is not just statistical; it is reflected in the user experience. A growing sentiment in the technical community is that new models are not always "reliably better" than their predecessors for all tasks, and the improvements are far less obvious to the average user than the jump from GPT-3.5 to GPT-4 was [17].
The industry's strategic response to these challenges is telling. The widespread adoption of more efficient architectures like Mixture-of-Experts by Meta and Mistral, and the focus on smaller, specialized models by Google and Mistral, are not just technical innovations but economic necessities [9]. These moves signal a tacit acknowledgment that the brute-force scaling of dense Transformer models is no longer a sustainable or efficient path to progress.
In this context of plateauing technical capabilities, the industry's narrative is also shifting. The discourse is increasingly moving away from the pursuit of autonomous Artificial General Intelligence (AGI) and toward the concept of AI as a "digital colleague", as we have covered across a number of earlier articles [20], [21]. The shift from a replacement-oriented mindset to one of human-AI collaboration is a cornerstone of the AI-native enterprise. Rather than viewing human interaction, verification, and oversight as a limitation, this perspective frames it as a core feature of a new operating model. In this model, AI agents act as "digital colleagues," and the true value is unlocked through a "protocol layer" that allows for seamless, safe, and efficient coordination between human and digital teams. This pivot is not necessarily a marketing strategy but a reflection of a maturing technology cycle, where the focus moves from technological capability to designing intentional, outcome-oriented workflows that orchestrate human and machine intelligence effectively.

“ Incremental gains are valuable, but they won’t carry us to the next horizon. Our focus is on experimenting with hybrid architectures now, so we’re ready when the next real breakthrough arrives. ”
The inherent architectural limits of the transformer
The performance plateau and diminishing returns from scaling are not merely problems of resource constraints. They are symptoms of deeper, more fundamental limitations baked into the transformer architecture itself. While this architecture revolutionized natural language processing by enabling parallel computation, its core design principles contain inherent flaws that prevent it from achieving true, robust intelligence. The industry's current challenges are a direct consequence of pushing this architecture to its absolute limits.
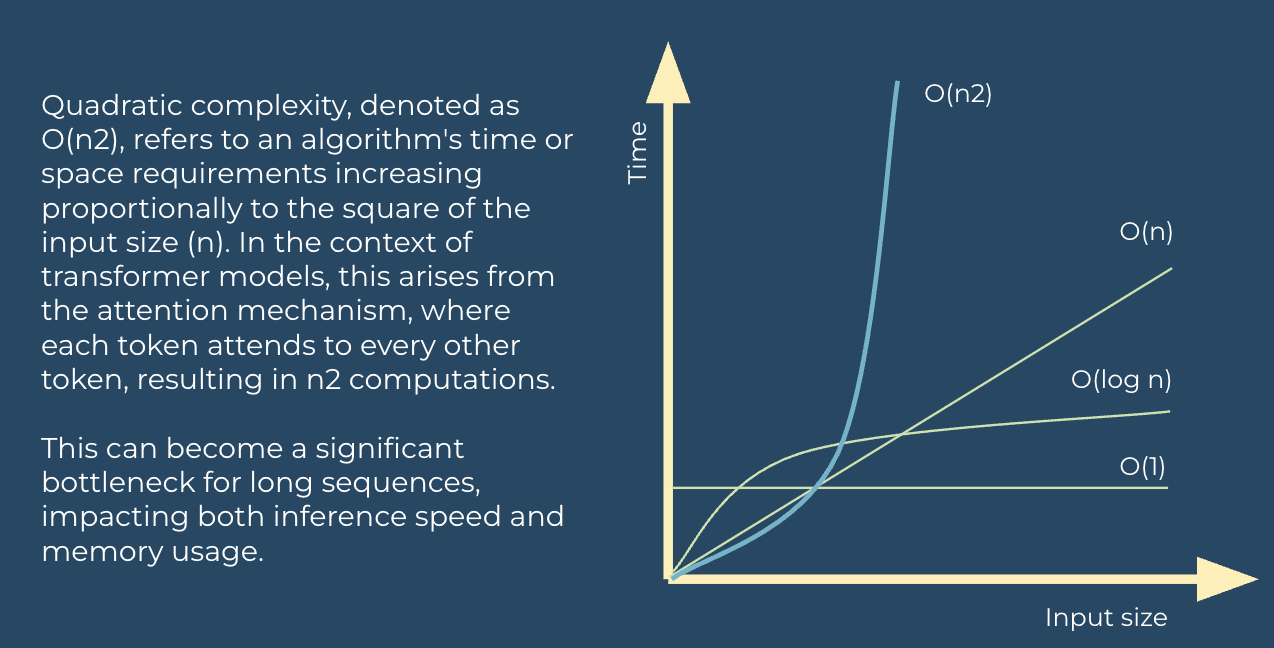
Flaw 1: “Quadratic complexity”
The most widely discussed limitation of the transformer is the computational complexity of its self-attention mechanism. In order for the model to understand the context of a sequence, every token must attend to every other token. This all-to-all comparison results in computational and memory costs that scale quadratically with the length of the input sequence, represented as O(n2) [22]. This quadratic bottleneck makes it computationally infeasible to process very long contexts; such as entire books, large codebases, or high-resolution videos, without resorting to approximation techniques like sliding windows or sparse attention, which are ultimately patches on a fundamentally inefficient design [23]
Flaw 2: Failure of compositional reasoning
A more profound weakness, however, lies in the transformer's inability to perform reliable compositional reasoning. Technical analysis has revealed that a single transformer attention layer is provably incapable of reliably computing the composition of functions, a basic building block of logical thought [24]. For example, to answer the question "Who is Jens’ maternal grandmother?", a system must compose the function mother(mother(Jens). Due to an information bottleneck inherent in the attention mechanism, a transformer cannot reliably perform such multi-step logical operations when the set of possible entities (the domain) is sufficiently large [24].
This limitation has a very practical consequence: hallucinations. When a transformer is faced with a query that requires multi-step reasoning, its architecture prevents it from systematically deducing the answer. Instead, it falls back on its primary strength: statistical pattern matching. It generates a response that is statistically plausible based on the patterns in its training data, but which may be logically unsound or factually incorrect [25]. This explains why models can generate fluent, confident, and yet completely wrong answers. As critics have long argued, these systems are powerful "function approximators" that mimic human language without a genuine, underlying model of the world or the ability to reason about it [26]. The problem of unreliability, therefore, is not a bug that can be easily fixed with more data, but a direct feature of the architecture's design.
Flaw 3: Lack of recursion and hierarchy
Finally, the feedforward and parallel nature of the transformer architecture, which was its key advantage over sequential models like RNNs, also imposes a structural limitation. The number of computational transformations that can be applied to an input is strictly bounded by the depth of the model. This prevents the architecture from performing true recursive computation or effectively modeling deeply hierarchical structures, which are central to human language and thought. While RNNs suffered from other issues like vanishing gradients, they could theoretically maintain and update an internal state over an unbounded number of steps. The transformer's fixed-depth processing represents a fundamental constraint on its reasoning capabilities [25].
The dominance of the transformer architecture, despite these flaws, can be partly attributed to its extraordinary synergy with modern hardware. The architecture's reliance on large, dense matrix multiplications for its attention mechanism is perfectly suited to the massively parallel processing capabilities of GPUs and TPUs [27]. This has led to the perspective that transformers are "GNNs currently winning the hardware lottery". Their success may be as much a product of this hardware alignment as any intrinsic superiority as a model for intelligence. This suggests that the next leap forward may require not just a new architecture, but one that either aligns with a new generation of hardware or is compelling enough to inspire its creation.
The next architectural paradigm
The transformer's limitations have catalyzed a vibrant and diverse search for its successor. Rather than a single, unified effort, the field is exploring multiple architectural paradigms, each designed to solve a different core weakness of the current approach. These emerging architectures are not merely theoretical; they are powering a new generation of models that point toward a future beyond self-attention. Four promising directions currently are state space models, neuro-symbolic AI, world models, and GNNs.
State space models
State space models (SSMs) represent a direct assault on the transformer's primary bottleneck: quadratic complexity. Inspired by classical control theory, SSMs process sequential data with linear complexity, making them exceptionally efficient for long sequences [28]. The Mamba architecture improves upon earlier SSMs by incorporating a "selective scan" mechanism. This allows the model to dynamically decide whether to keep information from a given token in its compressed "state" or to forget it, effectively combining the linear-time efficiency of RNNs with the parallel training capabilities that made transformers so successful.
The primary advantage is a dramatic improvement in performance on tasks involving very long contexts, such as genomics, high-resolution video, and documents with millions of tokens, domains where transformers are computationally impractical [28]. Benchmarks show that Mamba is competitive with or even outperforms transformers of a similar size on many tasks, particularly those requiring long-range dependencies, while offering up to five times faster inference Another efficient sequence model, RWKV (Receptance Weighted Key-Value), re-imagines the LLM as a type of recurrent network, processing tokens sequentially with linear time updates, which can make it 10 to 100 times cheaper to run on long inputs.
Neuro-symbolic architectures
Neuro-symbolic AI (NSAI) directly confronts the transformer's weakness in logical reasoning. NSAI systems integrate two distinct paradigms of artificial intelligence: neural networks, which excel at learning patterns from vast amounts of data, and symbolic AI, which uses explicit rules and logic for formal reasoning. This hybrid approach is often analogized to a model of human cognition, with the neural network providing fast, intuitive "System 1" thinking and the symbolic component providing slow, deliberate "System 2" reasoning [29].
By offloading complex logical deductions to a dedicated symbolic engine, NSAI systems can achieve a level of accuracy, reliability, and explainability that is unattainable for purely neural models. This approach directly mitigates the problem of hallucination by grounding the AI's outputs in a set of verifiable logical rules.[30] Research in this area is exploring various integration strategies, with a particularly promising direction being hybrid models where an LLM can call an external symbolic solver (like a theorem prover or calculator) as a tool [29]. On benchmarks that require strict logical consistency, such as Raven's Progressive Matrices, neuro-symbolic approaches have been shown to significantly outperform even the most advanced LLMs [31].
World models
The concept of World Models, championed by AI pioneers like Yann LeCun, addresses a more philosophical limitation of LLMs: their lack of grounding in physical reality [32]. An LLM trained exclusively on text develops a sophisticated model of language but has no inherent understanding of the world that language describes [31]. World models aim to solve this by building AI systems that learn an internal, predictive model of how the world works. The primary learning method is self-supervised learning from sensory data, particularly video, rather than text [33].
By observing the world, an AI with a world model can learn concepts like object permanence, intuitive physics, and causality [34]. This allows the system to plan, reason about the consequences of its actions, and develop a form of common sense that cannot be derived from statistical text patterns alone. While still in early stages, systems like Google DeepMind's Genie 3, which can generate interactive, playable environments from simple prompts, represent the first steps toward AI that can simulate possible futures to inform its decisions [14].
Graph neural networks
Graph Neural Networks (GNNs) offer a different perspective by focusing on explicitly modeling relationships. GNNs operate on data structured as a graph, consisting of nodes (entities) and edges (the relationships between them) [34]. Their core mechanism, "message passing," allows nodes to iteratively aggregate information from their neighbors, making them naturally suited for tasks involving complex relational data, such as social networks, molecular biology, and knowledge graphs [35].
A compelling technical argument reframes the transformer as a specific, and rather inefficient, type of GNN [36]. In this view, the transformer's self-attention mechanism is mathematically equivalent to a GNN operating on a fully connected graph, where every token is a node connected to every other token [37]. This implies that the Transformer is a brute-force approach that ignores any inherent structure in the data (such as the syntactic structure of a sentence) and instead attempts to learn all possible relationships from scratch. This suggests that architectures like GNNs, which can leverage explicit, sparse relational structures, could be far more efficient and powerful for knowledge-intensive tasks.
The exploration of these diverse architectural paths indicates that the future of AI is unlikely to be monolithic. Each paradigm solves a different piece of the intelligence puzzle: SSMs for efficiency, NSAI for logic, World models for causality, and GNNs for relations. The next frontier model will likely be a hybrid system that integrates elements from these different approaches, as already seen in models like Jamba, which combines transformer and Mamba layers. This shift also signals the re-emergence of a foundational debate in AI between pure connectionism (the belief that intelligence emerges from scaling large networks) and hybrid approaches that see value in incorporating explicit knowledge, structure, and reasoning. The current plateau is forcing the field to move beyond scaling and re-engage with these fundamental questions about the nature of intelligence itself.
The next step is to move from incremental iteration to foundational innovation
The next step is to move from incremental iteration to foundational innovation. The 2025 landscape of foundation models presents a paradox. On one hand, capabilities have never been higher, with models from OpenAI, Google, Meta, and others setting new state-of-the-art benchmarks in a relentless race. On the other, this progress feels incremental; the result of massive engineering effort and resource expenditure that is yielding diminishing returns. The great leaps in capability that once defined the field have been replaced by a steady, but less inspiring, climb up the leaderboards.
This slowdown is not a temporary lull but a predictable consequence of hitting the limits of the transformer architecture. The unsustainable economics of scaling, coupled with fundamental weaknesses in areas like compositional reasoning and long-context processing, show that simply building bigger versions of the same models is no longer a viable path to the next level of artificial intelligence. Efficiency-focused techniques like Mixture-of-Experts, and AI’s role as an autonomous agent, “digital colleagues”, are natural consequences of this plateau.
There is significant value to derive from agentic AI. But the path beyond lies not in further iteration on the current paradigm, but in foundational innovation. The architectural alternatives explored above address core weaknesses of the transformer. The future is unlikely to be dominated by a single new architecture, but rather by hybrid systems that combine the strengths of diverse approaches.
As noted in Algorithma’s earlier analysis, there is significant value in leveraging LLM capabilities to build AI agents, or digital colleagues, that integrate directly into workflows. When paired with the right governance and architectural design, these agents can take on responsibility spans that grow over time, complementing human teams rather than replacing them.
What to do in the short term;
- Invest smartly in agentic AI: Simply put, just get going. Leverage agentic AI where it makes sense to drive operational excellence and customer interaction [38], [40]
- Audit model dependencies: Identify where your current AI stack is locked into a single model family and assess the risks of architectural obsolescence, avoid lock-in [39]
- Pilot hybrid architectures: Run controlled trials with at least one non-transformer-based system to explore potential efficiency and capability gains.
- Design for interoperability: Build integration layers that allow for model replacement or augmentation without wholesale re-engineering.
- Invest in agent governance: Establish processes for monitoring, scaling, and safely expanding the responsibility span of AI agents in production.
- Track architectural R&D: Dedicate resources to horizon scanning and partnerships that give early access to emerging architectures.
The end of the transformer’s undisputed reign is the beginning of a new era of architectural diversity. Leaders who act now to prepare for that shift will be best positioned to capture its benefits, and avoid being locked into the past.
In the near-term, we will likely see an evolution where the major players will climb in the value chain, building vertical applications on top of the foundational models, with a consolidation across a booming vibe-coded LLM wrapper ecosystem. This will impact investors, companies and enterprises. However, in the near term, we see the main value pocket for enterprises to be in applying the foundational models for bespoke business process automation - using both ready-made point solutions and custom implementations.
Sources
- [1] https://openai.com/index/introducing-gpt-5/
- [2] https://timesofindia.indiatimes.com/education/news/openais-gpt-5-replaces-all-previous-versions-what-students-need-to-know-about-the-smartest-ai-yet/articleshow/123215368.cms
- [3] https://medium.com/@adnanmasood/openais-gpt-5-is-here-a-deep-dive-into-the-system-card-for-ai-that-s-smarter-safer-and-faster-bca6effe5a8d
- [4] https://www.theneuron.ai/explainer-articles/gpt-5-is-here-heres-everything-you-need-to-know-so-far
- [5] https://www.creolestudios.com/gpt5-vs-gpt4o-vs-o3-model-comparison/
- [6] https://www.vellum.ai/blog/gpt-5-benchmarks
- [7] https://apnews.com/article/gpt5-openai-chatgpt-artificial-intelligence-d12cd2d6310a2515042067b5d3965aa1
- [8] https://ai.meta.com/blog/llama-4-multimodal-intelligence/
- [9] https://www.llama.com/
- [10] https://www.llama.com/models/llama-4/
- [11] https://mistral.ai/news/codestral-25-08
- [12] https://frenchtechjournal.com/vivatech-2025-mistral-ai-gets-cozy-with-nvidia/
- [13] https://research.google/blog/google-research-at-google-io-2025/
- [14] https://deepmind.google/discover/blog/genie-3-a-new-frontier-for-world-models/
- [15] https://arxiv.org/html/2506.23253v1
- [16] https://blogs.nvidia.com/blog/ai-scaling-laws/
- [17] https://medium.com/@adnanmasood/is-there-a-wall-34d02dfd85f3
- [18] https://www.siddharthbharath.com/gpt4-5-a-complete-review-and-comparisons
- [19] https://medium.com/@dbiswajitdatta/limitations-of-llm-models-03cc3d6645b6
- [20] https://www.ainvest.com/news/ai-redefined-teammate-digital-workforce-transformation-2507/
- [21] Designing the AI-native enterprise: protocols, digital colleagues, and the new stack
- [22] https://www.reddit.com/r/MachineLearning/comments/18qh1hp/discussion_in_this_age_of_llms_what_are_the/
- [23] https://www.reddit.com/r/MachineLearning/comments/hmbxrg/d_weaknesses_of_the_transformers/
- [24] https://arxiv.org/html/2402.08164v1
- [25] https://openreview.net/pdf?id=OCm0rwa1lx1
- [26] https://observer.com/2025/05/gary-marcus-disillusionment-ai/
- [27] https://arxiv.org/abs/2506.22084
- [28] https://thegradient.pub/mamba-explained/
- [29] https://en.wikipedia.org/wiki/Neuro-symbolic_AI
- [30] https://www.edps.europa.eu/data-protection/technology-monitoring/techsonar/neuro-symbolic-artificial-intelligence_en
- [31] https://www.university-365.com/post/meta-ai-vision-yann-lecun-insights-about-future-beyonds-llm
- [32] https://chatpaper.com/chatpaper/paper/173408
- [33] https://ai.meta.com/blog/yann-lecun-advances-in-ai-research/
- [34] https://medium.com/@ML-today/world-modeling-the-future-of-ai-ff8703daa220
- [35] https://graph-neural-networks.github.io/static/file/chapter21.pdf
- [36] https://en.wikipedia.org/wiki/Graph_neural_network
- [37] https://arxiv.org/abs/2506.22084
- [38] https://www.weforum.org/stories/2025/01/why-you-should-think-of-ai-as-a-teammate-not-a-tool-when-building-a-better-future/
- [39] Our Latest Thinking
- [40] Designing the AI-native enterprise, part 2: Leveraging AI agents to offset increasing cost of doing business